

Come abilitare / disabilitare la scansione del nostro sito web ai motori di ricerca utilizzando il file robots.txt
Allow or Disallow robots.txt
allow disallow sintassi
Robots.txt è un file inserito nella nostra web root directory, ovvero nella nostra directory principale, facilmente raggiungibile con un programma di FTP e modificabile con notepad.
Robots.txt viene utilizzato per istruire i motori di ricerca nella scansione del nostro sito web.
Robots.txt indirizza i motori di ricerca su quali file o cartelle ha il permesso di eseguire la scansione e quali cartelle o file lo spider del motore di ricerca non ha il permesso di entrare.
In questo Tutorial vi mostrerò come creare un file robots.txt e vi mosterò alcuni comandi per permettere o impedire che i crawler dei motori di ricerca visualizzino del vostro sito.
Tutti i motori di ricerca seguono le istruzione inserite nel file robots.txt, semplici comandi allow o disallow inseriti nel file robots.txt.
robots.txt – configurazione avanzata (SEO)
I Motori di ricerca vengono sul vostro sito web e prima di iniziare la scansione fanno un un rapido controllo al robots.txt, controllano se hanno il permesso di eseguire la scansione o se ci sono zone interdette – off limits.
Syntax to allow:
Sintassi per consentire:
1 2 | User-agent: * Allow: / |
Qui sopra diciamo ai motori di ricerca che hanno libero accesso di scansionare al nostro sito web.
Syntax to disallow:
Sintassi per non consentire:
1 2 | User-agent: * Disallow: / |
Con queste istruzioni diciamo ai motori di ricerca che non hanno libero accesso al nostro sito web e di conseguenza non possono procedere alla scansione del nostro sito.
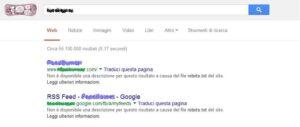
Questo sarà il risultato sui motori di ricerca:

robots.txt – configurazione avanzata (SEO)
Se notiamo bene nella foto del nostro esempio il motore di ricerca google oltre a dare il messaggio: “Non è disponibile una descrizione per questo risultato a causa del file robots.txt del sito.” in quarta riga lascia un piccolo messaggio che rimanda alla pagina specifica di Google robots.txt per il blocco degli URL con robots.txt Leggi ulteriori informazioni
Disallow specific folder:
disabilitare specifiche cartelle:
1 2 3 | User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ |
Con questo comando disciamo ai motori di ricerca ad indicizzare le carte wp-admin e wp-includes.
Disallow specific file:
disabilitare dei file specifici
1 2 | User-agent: * Disallow: /includes/db.php |
In questo modo comandiamo ai motori di ricerca di ignora il file db.php
Robot meta:
È inoltre possibile inibire ai robots l’indicizzazione del vostro sito tramire i meta tags nel vostro sito web presenti nell’head.
1 |
i meta sono particolari comandi inseriti nel vostro sito web ma non visibili
Disallow / allow particular search engine bot to crawl:
1 2 | User-agent: Googlebot Disallow: / |
Non permettere / permettere la scansione del vostro sito ad un particolare bot del motore di ricerca:
Con il file robots.txt possiamo decidere quali bot dei motori di ricerca possono scansionare il nostro sito e quali non hanno il permesso di scansionare. Una lista completa dei bot dei motori di ricerca è disponibili qui.
Usando questo comando stiamo vietando a Googlebot di eseguire la scansione e l’indicizzazione il vostro sito.
ESEMPI PRATICI:
Configurazioni Avanzate robots.txt
Bloccare le directory che iniziamo per…
1 2 | User-agent: * Disallow: /wp*/ |
Gli spider ignoreranno tutti le directory che iniziano per “wp”
(purtroppo questa funzione molto utile non viene recepita da tutti i motori di ricerca)
Bloccare alcuni file tramite l’estenzione:
1 2 | User-agent: * Disallow: /*.php$ |
Bloccare una o più immagini:
1 2 | User-agent: * Disallow: /images/nascondi.png |
1 2 | User-agent: Googlebot-Image Disallow: /images/nascondi.png |
1 2 | User-agent: Googlebot-Image Disallow: / |
Così facendo stiamo dicendo al bot di google delle immagini di ignorare il nostro sito.
Blocchi con eccezioni:
1 2 3 | User-agent: * Allow: /directory-da-escludere/file-da-non-escludere.html Disallow: /directory-da-escludere/ |
Robots.txt non basta
Purtroppo non tutti i crawl seguono le regole del vostro robots.txt quindi alcuni motori di ricerca (minori), anche se utilizzate Disallow: / in robots.txt , indicizzeranno il vostro sito.
Spero che abbiate trovato questo tutorial su robots.txt utile, per favore segnalateci ai vostri amici e se avete dubbi contattateci o commentate, risponderemo a tutti.
robots.txt

Robots.txt configurazione avanzata per webmaster
Parola di SEO



